Projekt: Vorhersage von Diabetes bei Patienten mithilfe von Machine Learning in MATLAB
Machine Learning · MATLAB · Klassifikation
-
Das Ziel des Projekts ist:
- die Entwicklung eines maschinellen Lernmodells in MATLAB,
- das Training des Modells mit Patientendaten sowie
- die Bereitstellung des Modells als App oder Anwendung, die auf Basis klinischer Daten vorhersagt, ob ein Patient an Diabetes leidet.
- 1- Datenbeschreibung:
-
Der Datensatz, der in diesem Projekt verwendet wird, basiert auf gegebenen Merkmalen bzw. diagnostischen Messwerten und berücksichtigt Patientinnen, die mindestens 21 Jahre alt sind und der Pima-Indianer-Bevölkerung angehören.
-
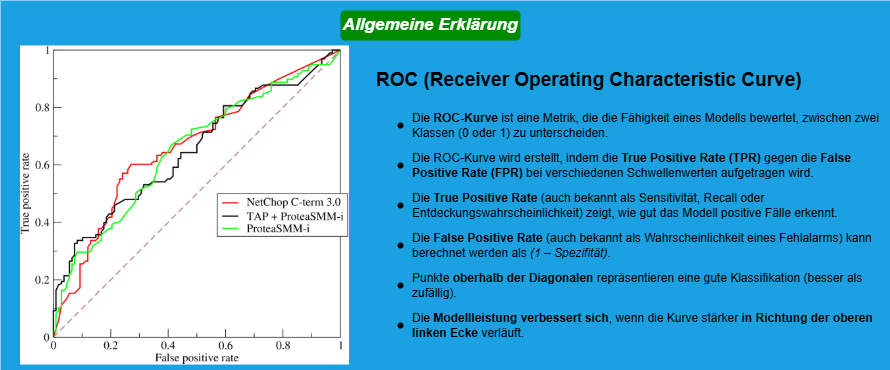
Eingabedaten (INPUTs):
- Pregnancies: Anzahl der Schwangerschaften
- GlucosePlasma: Glukosekonzentration zwei Stunden nach einem oralen Glukosetoleranztest (mg/dl)
- BloodPressure: Diastolischer Blutdruck (mm Hg)
- SkinThickness: Dicke der Trizeps-Hautfalte (mm)
- Insulin: Serum-Insulin zwei Stunden nach der Nahrungsaufnahme (μU/ml)
- BMI: Body-Mass-Index (Gewicht in kg / (Größe in m)²)
- DiabetesPedigreeFunction: Maß für die familiäre Diabetesbelastung
- Age: Alter (Jahre)
-
Ausgabedaten (OUTPUT):
- Diabetes oder kein Diabetes
(1 = Diabetes, 0 = kein Diabetes)
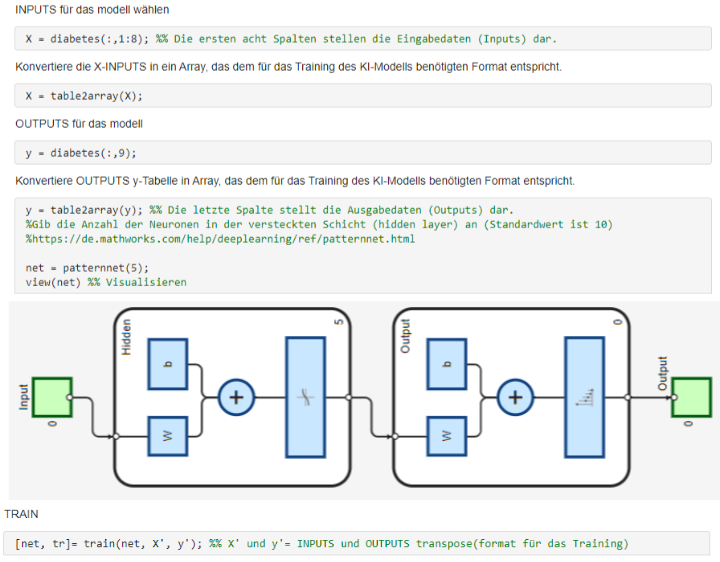
- MATLAB:
Wobei die ersten acht Spalten unsere X-Eingaben sind und die letzte Spalte unsere Y-Ausgabe ist.
- 2- Entwicklung des Modell (Künstliches Neuron)
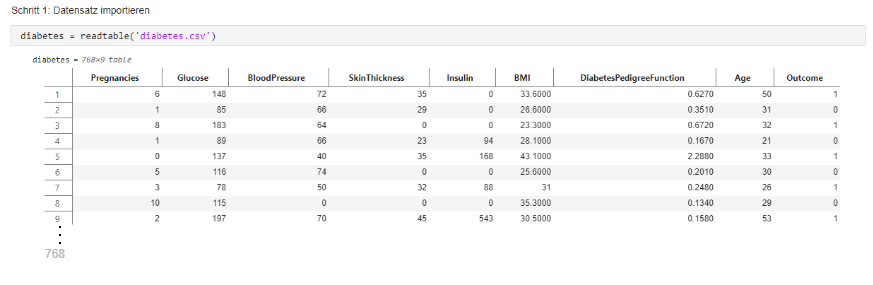
Das Modell besteht aus mehreren Eingangsvariablen (Inputs) \[ x_1, x_2, x_3, \dots, x_n \] den dazugehörigen Gewichten \[ w_1, w_2, w_3, \dots, w_n \] und einem Bias-Term \( b \).
In dieses „Diabetes Prediction“-Modell arbeitet das Neuron so :
\[ y = f(\text{Glukose} \cdot w_1 + \text{BMI} \cdot w_2 + \text{Alter} \cdot w_3 +...+ b) \]
- - Wenn y einen hohen Wert hat (z. B. > 0.5), deutet das Modell auf Diabetes = Ja (1) hin.
- - Wenn y niedrig ist (z. B. < 0.5), dann kein Diabetes (0).
Bedeutung der Komponenten
| Symbol | Bedeutung | Beschreibung |
|---|---|---|
| \( x_i \) | Eingangsvariablen | Patientendaten (z. B. Glukose, BMI, Alter etc.) |
| \( w_i \) | Gewichte | Bestimmen die Bedeutung jedes Eingabewerts |
| \( b \) | Bias | Verschiebt die Aktivierungsfunktion, um das Modell flexibler zu machen |
| \( f \) | Aktivierungsfunktion | Wandelt die gewichtete Summe in eine Ausgabe um (z. B. Sigmoid, ReLU) |
| \( y \) | Ausgabe | Vorhersage des Neurons (z. B. Wahrscheinlichkeit für Diabetes) |
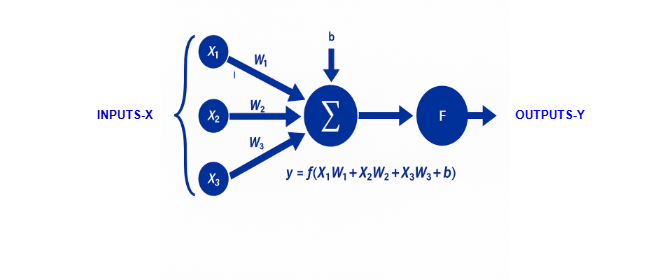
- 3- Modelltraining, Testen und Validieren
Das Ziel des Trainings ist es, ein Modell zu erstellen, das aus Beispieldaten (Patientendaten) lernt, Diabetes vorherzusagen.
Dazu werden die Eingabedaten (Glukos, Alter, ...) und die Ausgabedaten Y verwendet, um optimale Gewichtungen \( W \) und den Bias \( b \) zu bestimmen. Dadurch „lernt“ das Modell, Zusammenhänge zwischen den Eingangsvariablen (z. B. Glukose, BMI, Alter) und der Zielvariable (Diabetes ja/nein) zu erkennen.
MATLAB:
- Bewertung der Leistung des Modells.
1- KPIs - Confusion Matrix
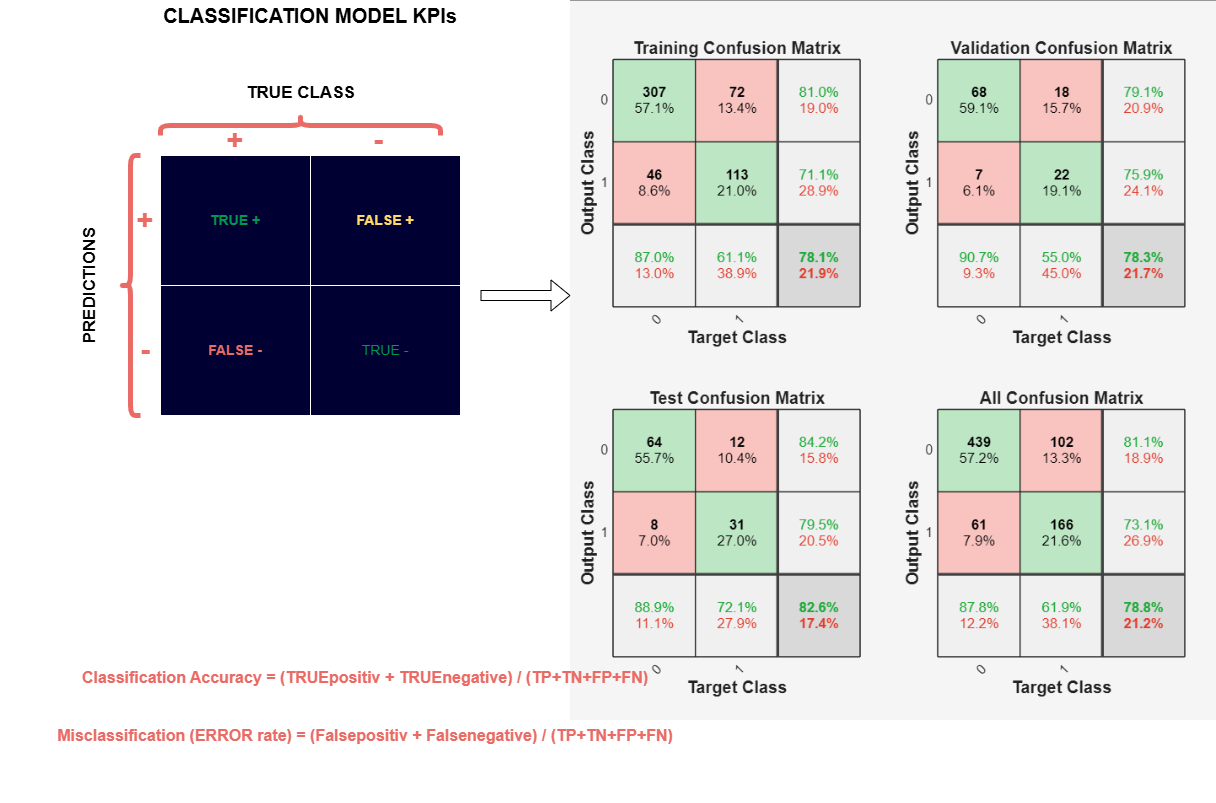
. Allgemeine Bedeutung
Eine Confusion Matrix zeigt, wie oft das Modell richtig oder falsch klassifiziert hat:
- Grün = richtige Klassifikationen
- Rot = falsche Klassifikationen
- Die Zeilen sind die vorhergesagten Klassen (Output Class).
- Die Spalten sind die tatsächlichen Klassen (Target Class).
. Training Confusion Matrix
- Genauigkeit (Accuracy): 78.1 %
- Klasse 0 (gesund) wird zu 57,1 % richtig erkannt.
- Klasse 1 (diabetisch) wird zu 21 % richtig erkannt.
➡️ Bewertung:
Das Modell lernt die Muster recht gut, aber es hat noch Schwierigkeiten mit Klasse 1(diabetisch) (relativ viele Fehlklassifikationen). Es könnte ein Klassenungleichgewicht vorliegen oder die Merkmale von Klasse 1 sind schwerer zu unterscheiden.
. Validation Confusion Matrix
- Genauigkeit (Accuracy): 78.3 %
- Klasse 0 (gesund) wird zu 59,1 % richtig erkannt.
- Klasse 1 (diabetisch) wird zu 19,1 % richtig erkannt.
➡️ Bewertung:
Die Leistung bleibt ähnlich wie im Training → kein starkes Overfitting(Trainingsdaten fast „auswendig gelernt). (relativ viele Fehlklassifikationen). Aber die Klasse 1 bleibt deutlich schwächer, das Modell bevorzugt also vermutlich Klasse 0 (Bias).
. Test Confusion Matrix
- Genauigkeit (Accuracy): 82,6 %
- Klasse 0 (gesund) wird zu 55,7 % richtig erkannt.
- Klasse 1 (diabetisch) wird zu 27 % richtig erkannt.
➡️ Bewertung:
Das Modell generalisiert aber gut! Die Genauigkeit auf Testdaten ist sogar leicht höher, was auf einestabile Trainings- und Validierungsstrategie hinweist. Die Unterscheidung von Klasse 1 klappt hier etwas besser.
. Overall (All Confusion Matrix)
- Gesamtgenauigkeit: 78,8 %
- Keine Überanpassung (Training, Validation, Test sind ähnlich)
- Verbesserungspotenzial:
- Datenausgleich zwischen den Klassen (z. B. SMOTE, Class Weights)
- Keine Überanpassung (Training, Validation, Test sind ähnlich)
- Alternative Modelle (z. B. Random Forest, Gradient Boosting) ausprobieren
➡️ Gesamtbewertung:
- Gute, robuste Modellleistung (≈ 79 % Accuracy)
- Klasse 0 (gesund) wird zu 57,2 % richtig erkannt.
- Klasse 1 (diabetisch) wird zu 21,6 % richtig erkannt.
2- Receiver Operating Characteristic (ROC)