1. Projektziel
Ziel dieses Projekts war es, eine komplette Anwendung inkl. Backend-Services wie in einer professionellen Umgebung aufzusetzen – zuerst manuell (für Verständnis & Troubleshooting), danach vollautomatisch (reproduzierbar, konsistent, schnell).
- Manuell: Services installieren, konfigurieren, Ports öffnen, Logs analysieren
- Automatisiert:
vagrant up→ Infrastruktur + Deployment in einem Schritt - Nachweis: Funktionierende End-to-End Kommunikation (Web → App → DB/Cache/Queue)
Dieses Projekt zeigt bewusst die Entwicklung von „Manual Ops“ zu „Infrastructure Automation“ – inklusive realer Debugging-Fälle.
2. Systemarchitektur
Die Architektur folgt einem klassischen Pattern: Reverse Proxy vorne, Application Server in der Mitte, Data Services im Backend.
User Flow: Wie die Services konkret zusammenarbeiten
Der Ablauf ist bewusst wie in einer echten Produktionsarchitektur aufgebaut: ein zentraler Entry Point (Nginx), ein Application Server (Tomcat) und dahinter spezialisierte Backend-Services (DB, Cache, Queue).
-
1) User → web01 (Nginx)
Der User ruft die Anwendung im Browser auf (http://192.168.56.11).
Nginx ist der einzige öffentlich erreichbare Einstiegspunkt und nimmt die HTTP-Anfrage entgegen. -
2) Nginx → app01 (Tomcat)
Nginx leitet die Anfrage per Reverse Proxy anapp01:8080weiter (proxy_passim Nginx-Config).
Vorteil: Die App-VM muss nicht direkt öffentlich erreichbar sein – Nginx „schützt“ den App-Server. -
3) Tomcat verarbeitet die Anfrage (Business Logic)
Auf app01 läuft Tomcat. Dort ist die Web-App alsROOT.wardeployed. Tomcat verarbeitet Login/Views/Requests und entscheidet, welche Daten benötigt werden. -
4) Tomcat ↔ db01 (MariaDB)
Wenn die Anwendung Daten dauerhaft speichern oder lesen muss (z.B. User/Profiles/Records), verbindet sie sich mit MariaDB auf db01:3306 (über JDBC).
DB = “Single Source of Truth” für persistente Daten. -
5) Tomcat ↔ mc01 (Memcached)
Für schnelle Zugriffe (z.B. Sessions, häufig genutzte Daten oder Cache-Objekte) nutzt die App Memcached auf mc01:11211.
Das reduziert DB-Last und macht Antworten schneller. -
6) Tomcat ↔ rmq01 (RabbitMQ)
Für asynchrone Aufgaben (z.B. Events, Background-Jobs, Verarbeitung im Hintergrund) sendet die App Nachrichten an RabbitMQ auf rmq01:5672.
Dadurch kann die App Anfragen schnell beantworten, während Aufgaben im Hintergrund abgearbeitet werden. -
7) Antwort zurück zum User
Tomcat erzeugt die HTTP-Response (HTML/JSON) → Nginx → Browser. Der User sieht die Seite, während Daten aus DB/Cache/Queue je nach Bedarf verwendet wurden.
Wichtig:
Jede VM hat eine klar definierte Rolle. Nginx ist der zentrale Entry Point,
Tomcat ist die Business-Schicht, und DB/Cache/Queue liefern spezialisierte Funktionen.
Genau diese Trennung macht das Setup realistisch, skalierbar und gut wartbar.
Warum Multi-VM? Saubere Trennung der Verantwortlichkeiten, klare Abhängigkeiten und realistische Produktions-Architektur.
3. Setup manuell (Troubleshooting & Verständnis)
Im ersten Schritt habe ich jede Komponente manuell installiert, um Abhängigkeiten, Ports und Logs zu verstehen:
- db01: Datenbank-Setup (Schema Import, User/Grants)
- mc01: Cache-Setup (Binding/Port, Systemd Service)
- rmq01: Message Broker (User, Permissions, Remote Access)
- app01: Build + Deployment (Maven → WAR → Tomcat)
- web01: Reverse Proxy (Nginx upstream → app01:8080)
Beim initialen Setup schlug das Deployment auf Tomcat 10 fehl (Jakarta vs. javax).
Logs zeigten:
NoClassDefFoundError: javax/servlet/ServletContextListenerFix: Wechsel auf Tomcat 9 (kompatibel mit
javax.servlet).
4. Automatisierung (Vagrant + Shell Provisioning)
Nach erfolgreichem manuellen Aufbau wurde das Setup in Provisioning-Skripte übertragen.
Damit ist das gesamte System reproduzierbar: vagrant up erstellt und konfiguriert alles automatisch.
Beispiel: Projektstruktur
Diese Struktur entspricht meinem aktuellen Repository (Setup + Automation im selben Projekt).
PROFILE/
├── src/ # Application source code (Java / Spring)
├── target/ # Maven Build Output (WAR nach mvn package)
├── ansible/ # (optional) späterer Ausbau / Experimente
└── vagrant/
└── Automated_provisioning/
├── Vagrantfile # Orchestriert alle VMs + Provisioning
├── application.properties # App-Config: DB/Cache/Queue Hosts & Ports
├── backend.sh # Build/Deploy Schritte (Repo, Maven, WAR)
├── mysql.sh # Datenbank Setup (MariaDB/MySQL)
├── memcache.sh # Memcached Setup
├── rabbitmq.sh # RabbitMQ Setup
├── nginx.sh # Nginx Reverse Proxy Setup
├── tomcat.sh # Tomcat Setup (Linux VM)
└── tomcat_ubuntu.sh # Tomcat Setup (Ubuntu Variante, falls genutzt)Der Vagrantfile erstellt die VMs (db01/mc01/rmq01/app01/web01) und ruft die jeweiligen Provisioning-Skripte auf.
Jedes Script installiert und konfiguriert genau einen Service (inkl. Ports/Firewall), sodass am Ende vagrant up ein vollständiges, lauffähiges System liefert.
5. Validierung
Nach dem automatisierten Provisioning wird das System mit technischen Checks validiert. Diese Prüfungen entsprechen typischen DevOps-Health-Checks in realen Umgebungen.
Service-Status & Ports
Überprüfung, ob alle relevanten Services laufen und auf den erwarteten Ports erreichbar sind.
# Service status (auf den jeweiligen VMs)
systemctl status nginx
systemctl status tomcat
systemctl status mariadb
systemctl status memcached
systemctl status rabbitmq-serverProvisioning – One-Command Setup
Sichtbarer Nachweis des automatisierten Setups mit vagrant up.
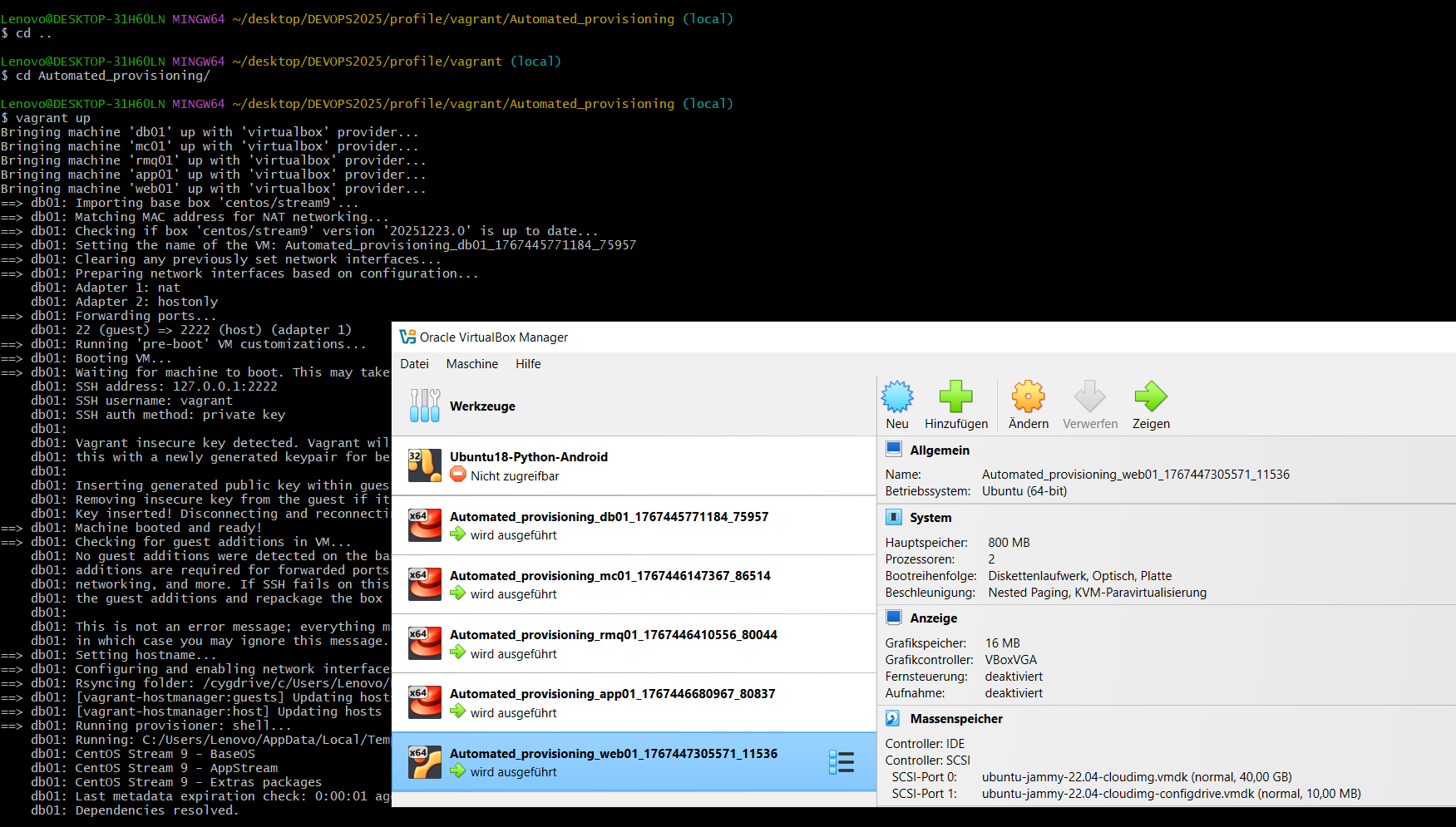
|
End-to-End Test (HTTP Response)
Technischer Nachweis, dass die Anwendung über den Reverse Proxy erreichbar ist.
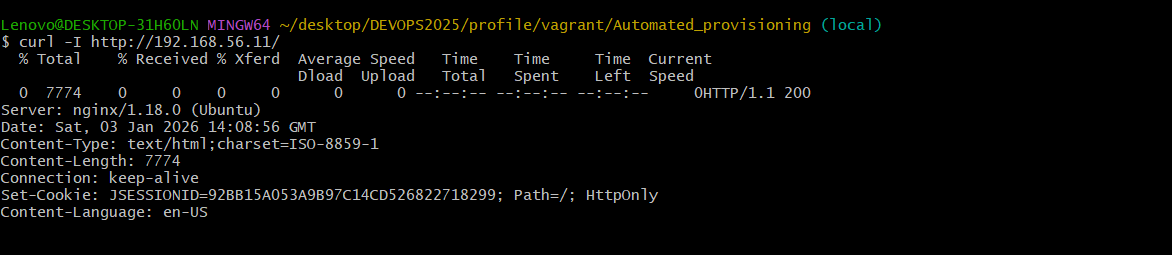
|
curl -I http://192.168.56.11 liefert HTTP 200 OK.
Die Anfrage wird über Nginx an Tomcat weitergeleitet,
inklusive Session-Handling.
Wichtig:
Dieses Projekt zeigt nicht nur Automatisierung, sondern auch
systematisches Validieren.
Tests mit curl und Service-Status-Prüfungen sind typische
Werkzeuge in CI/CD-Pipelines und Produktions-Health-Checks.
6. Warum diese technischen Entscheidungen?
- Vagrant – schneller, reproduzierbarer Multi-VM Lab-Aufbau
- Shell Provisioning – leichtgewichtig, transparent, gut für Portfolio
- Nginx – Reverse Proxy als Single Entry Point
- Tomcat 9 – Kompatibilität mit
javax.servlet-basierten Anwendungen - Memcached / RabbitMQ – typische Backend-Services in realen Architekturen
7. Lernziele & DevOps-Kompetenzen
- Linux: systemd, Services, Ports, Firewall, Logs
- Reverse Proxy Setup (Nginx upstream)
- Java Build & Deployment (Maven → WAR → Tomcat)
- Automatisierung: Infrastruktur reproduzierbar mit
vagrant up - Troubleshooting: Versionen/Kompatibilität, Log-Analyse, Service Dependencies
8. Nächster Schritt: AWS Migration
Das lokale Setup war entscheidend, um die Anwendung vollständig zu verstehen,
zu stabilisieren und zu automatisieren, bevor sie risikofrei nach Cloud migriert wurde.
Im nächsten Schritt wird die bestehende Java-Anwendung ohne Code-Änderungen
nach AWS migriert (Lift & Shift), inklusive EC2, Load Balancer, Security Groups,
S3 und IAM.